【更新完了】Developers Summit 2019レポ(2日目)
2019.2.15
というわけで2日目です。
1日目の記事はこちら。
2日目の資料はこちらで随時公開されるそうです。
本日の更新はセッション毎に書き上がり次第公開していきます。
よろしく。
【20:55追記】
更新完了しました。
今日は昨日にもまして6000字超え。
誰が読むんだこんなの
以下目次
【15-A-1】 ドラゴンクエストXを支える失敗事例(青山 公士[スクウェア・エニックス])
【15-B-2】 メンバーの成長とチャレンジのためにエンジニアリングマネージャーとして大切にしたこと(山本 学[ヤフー])
【15-E-3】 Entertainment x Tech~多くのアーティストとファンを繋ぐ技術と組織~(山田 真一[エイベックス])
【15-D-4】 OSS開発スタイルを取り入れて、効率的な開発を!~InnerSourceのススメ~(田中 裕一[GitHub])
【15-B-5】 Site Reliability Engineering at Google(中井 悦司[グーグル・クラウド・ジャパン])
【15-F-2】 Kubernetesを短時間で体験。IBM Kubernetesで遊んでみよう!(斎藤 和史[日本アイ・ビー・エム]/今関 靖一郎[日本アイ・ビー・エム システムズ・エンジニアリング])
【15-A-1】 ドラゴンクエストXを支える失敗事例(青山 公士[スクウェア・エニックス])
みんな大好きドラクエですよ。
やっぱりこのセッション、結構人気だったみたいで、こちとら時間ギリギリに行ったら個人スポンサーだってのに席が足りなくて一般席になっちまったぜ。
あとこのセッションは撮影禁止だったので写真がありません。
かなしい。
資料は配布予定だそうなので、みんなそれを見よう。
というわけで、本セッションでは、実際に起きた問題の事例を紹介して、教訓を共有するというもの。
どの事例もエンジニア的にあるあるーwという感じですが、まあ、実際の現場は大変だったろうなーと。
紹介された事例は以下の3つ。
- ある攻撃エフェクトの効果音がなり続ける現象
- 特定の攻撃エフェクトを修正した際に、効果音停止処理を止めていて、それの影響をうけていた
- 修正時に影響範囲は軽微との判断から、チケットを切らずに修正をしてしまった
- ドラクエチームはQA体制が整っており、チケットを切るとちゃんとクローズまで管理しているらしい
- 特定日時以降、ゲーム内の特定の場所で、パーティーのマッチングができない
- マッチング条件は毎月特定の時刻に自動更新されるようになっていた
- 条件は正常だったが、ゲームサーバーにはこんなコードが!!!!
if 日付 && 条件ハードコード { - 話はバグ発生から1年前。。。
- マッチング条件のデータフォーマットの変更が1年前にあった
- 移行のリリースタイミングが微妙なものがあり、1年後の6月分の条件をベタ書きして暫定対応した
- わーすれーてたーーーーーー
- 暫定対応は本完了までBTSチケットで管理しようという思い
- 釣りイベントで、釣った魚のサイズのランクの判定が正常になされないバグ
- 魚のサイズはmm単位で表され、魚のサイズのランクはノーマル/ビッグ/キングがある
- ここはC++とLuaで処理をしているが、C++はミリ単位でintで値をもち、Luaではメートル単位でdoubleで値を持つ -> 計算誤差がアヤシイ…
- コードをみると、数値計算による誤差を補正するコードが入っていた
- 補正計算式をよくよくよく見たら、まちがってたーーーーーー
- 補正計算は正常になされているとの思い込みから、かえってバグの発見が遅れてしまった。
いやー、なんかどれもこれもありそうだよね、という感じ。
聞いててなかなかにつらみが溢れる。
ちなみにスピーカーは、かの邪悪なキャラクター「キングボンビー」を世界で初めてプログラムした人、とのこと。
私は小学生の頃に、キングボンビーに借金の恐ろしさを身をもって教えられました。
【15-B-2】 メンバーの成長とチャレンジのためにエンジニアリングマネージャーとして大切にしたこと(山本 学[ヤフー])
ヤフーでマネジメントをやっている方のセッションです。
この方はマネジメント愛に溢れており、マネジメント全般に関わる課題を一つ一つ丁寧に解説されていました。
個人的には、マネージャーは担当分野がマネジメントというだけで、エンジニアと同じプレイヤーである、というのには完全同意した。
あとはパフォーマンスの方程式というのを初めて知った。
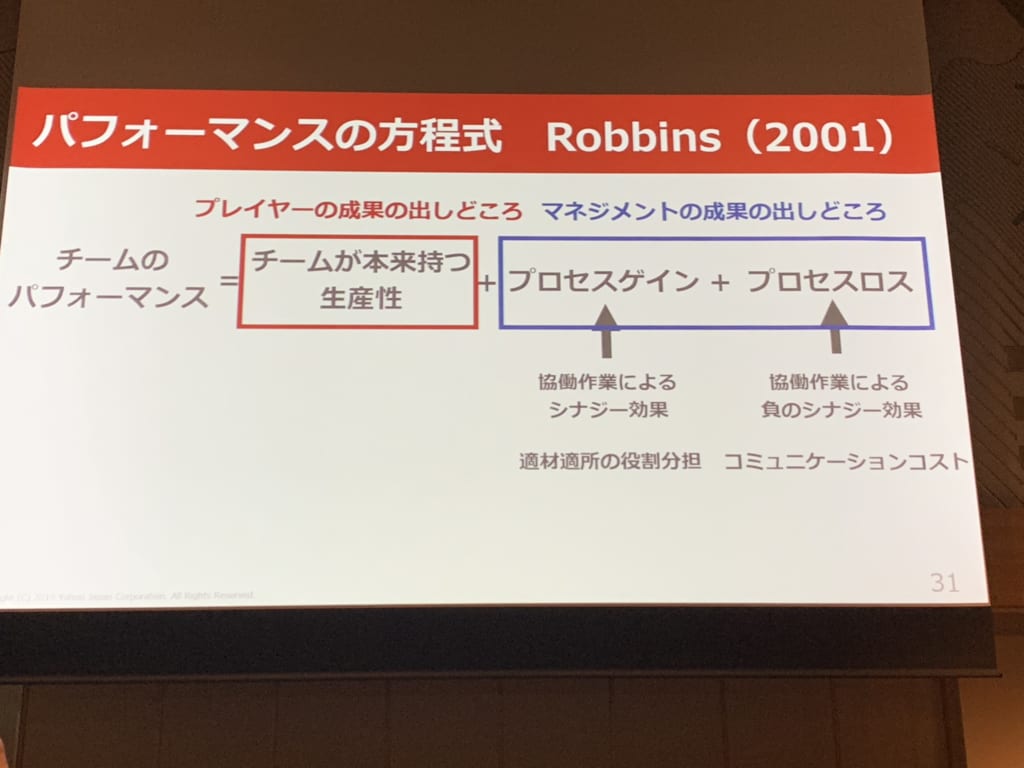
以下その他気になったところ。
- マネジメントは楽しい
- 1人じゃできない大きなことができるようになるのは楽しい
- 想像を超えるアウトプットが出てくると楽しい
- もともとプロダクトに興味を持ってエンジニアをやってきたが、チームにも興味を持つようになってマネジメントをするようになった
- 評価の本質は期待値と現状認識のすり合わせ
- あらかじめ自社の評価制度を明確に説明しておくのが大事
- 何をどう学べばいいのかわからない人には => ティーチングが有効
- 学んでいるが成長の実感が薄い人には => コーチングが有効
- 1on1をすると成長に気づきやすくなる
- エンジニアがアウトプットしやすい環境を作る
- 楽しくマネジメントするには
- 自己犠牲をしない
- コントロールできない物事にとらわれ過ぎない
- 孤独にならない(一番大事)
【15-E-3】 Entertainment x Tech~多くのアーティストとファンを繋ぐ技術と組織~(山田 真一[エイベックス])
スピーカーはイベントの撮影から制作、デザイン、システム開発など、今まで様々なことをやってきた方らしい。
何でも屋さんとのこと。
avexは小規模なウェブサイトが大量にあり、毎年のように作っては消え、作っては消え、を繰り返しているらしい。
毎年200〜300程度のウェブサイトが新規に作られ、現時点で稼働しているのが500程度あるらしい。
しかも昔から運用している(avexは今年で30周年とのこと)ので、古いサイトだとクラウド何それ美味しいの状態で、ウェブサイトのステークホルダーもたくさんいて、まだまだフルクラウドへの移行途中らしい。
となると、トラフィックによってはウェブサイトが危ないこともあるらしく、そのため常々監視を行なっているとのこと。
avexならではだなーと思ったのは、snsの「いいね」数とか、「フォロワー」数とかもアーティスト毎に監視していて、自然発生的なバズがおきても対応できるような体制を組んでいるとのこと。
また、ウェブサイト以外にも、扱う技術は多岐に渡っている模様。

その中で、avex自体は大量のエンジニアを抱えているわけではなく、技術部門が社内アーキテクトとして、企画側と開発を委託する外部パートナーとの調整を行うこともあるらしい。
そこでは、どうしても予算やスケジュールに合致するパートナーに開発委託するだけのことが多く、課題も多いそう。
そのため、avexは組織改革を行い、技術部門をCEO直轄部門にして権限を与え、専門性の高い人材を採用することで、ただの調整役にならないアーキテクトの育成につとめているとのこと。
【15-D-4】 OSS開発スタイルを取り入れて、効率的な開発を!~InnerSourceのススメ~(田中 裕一[GitHub])
InnerSourceってなんじゃらほい、と思って、とりあえず聞いてみたセッション。
実際聞いてみたら、結構面白く、今日イチおすすめのセッションかもしれない。
本セッションで初めて知ったのだが、InnerSourceという言葉は、OpenSourceという言葉と対になるもので、OpenSourceと同じような考え方・手法をprivateな領域でも採用しよう、という考え方らしい。
具体的には、例えば社内全体にシステムを公開し、プロジェクト外の人からも広くプルリクを受け入れるようにしてシステムを改善していく、など。
githubはそういうInnerSourceの考え方が徹底しているらしく、例えばスピーカーがgithubで働き始めた時には、まず最初に自分のプロジェクトが作られ、そこにやるタスクをissueベースで追加され、それをcloseしていくことで初期設定とかを済ませていくようになっていたらしい。
また、githubは全ての社内ドキュメントはgithub上でで管理されており、一部間違っていた箇所に対してスピーカーがプルリクを送ってみたところ、レビュアーが自動で設定され、CIが走ってマークダウンの静的解析やスタイルチェックが行われ、botが走って目次が自動生成されて、5分ぐらいでレビュアーから反応がきた、とのこと。
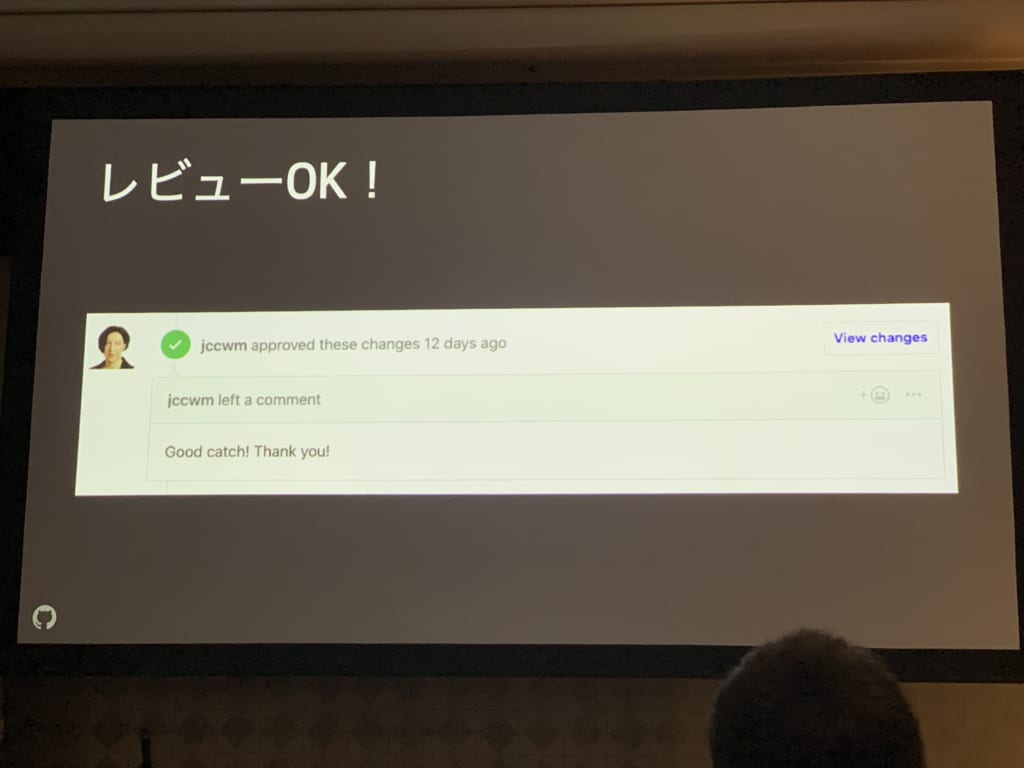
Good catch!ワロタ。
社内ドキュメントでさえこの本気度である。
とにかく無駄なことは徹底的に排除しようという強い意思を感じて、とてもエモみがあふれる。
こんな感じでOpenSourceの手法を取り込んだInnerSourceだが、元はPayPalがやり始めた考え方らしい。
InnerSourceのゴールは主に3つあり、
- コードの再利用
- チームを跨いだコラボレーション
- 品質の高いソフトウェアを高速に開発する
ということらしい。
このセッションでは、これらを実現するための3つの手法について話していて、
- 情報を共有する基盤を統一すること
- コントリビュートの仕方を明確にすること
- ワークフローの自動化をすること
をあげていた。
githubの例だと、
- 全てのリソースをgithub上に集約することでリソースの再利用性を高め
- 社内コントリビュートを推進することでチーム間のコラボレーションを計り
- ワークフローをgithubの機能を駆使して自動化することでプロジェクトに注力できるようにしている
という感じらしい。
セッションの中では、InnerSourceを最初に提唱したPayPalの事例もあげながら、InnerSourceの取り組みについて発表していた。
詳しくはInnerSourceについてのe-bookやコミュニティがあるので、みてみると良いとのこと。
e-book
Getting Started with InnerSource
Understanding the InnerSource Checklist
コミュニティ
InnerSource Commons
また、そもそもオープンソースの手法とかって何があるんだっけ?ってのには、こちらを参考にするとよいとのこと。
Open Source Guides
(最後にスピーカーは、このOpen Source Guidesの日本語訳のプロジェクトを行なっているらしい。ぜひこちらも機会があればcontributeしてほしいとのこと)
【15-B-5】 Site Reliability Engineering at Google(中井 悦司[グーグル・クラウド・ジャパン])
今をときめくSREのセッションです。
再び写真撮影禁止のセッションだったので、今回も写真はありません。
また、セッション内容は、基本的にこちらの書籍に基づいた内容であるとのこと。
さて、このセッションでは、まずはスピーカーから最初に軽くGoogleの説明と、内部基盤の説明がありました。
この中でちょっと面白いと思ったのは、Googleは世界中のデータセンターは全て同じ仕組みで動くようにしており、Kubernetesに似たコンテナ技術(Borg)を使って、世界中どこでも全く同じようにシステムの構築ができるようになっている、とのこと。
ちなみにこのBorg、Kubernetesの元になったもので、Googleの担当者がBorgをオープンソース向けに改修したものがKubernetesとのこと。
また、全てのプロジェクトを単一のリポジトリで管理している、というのも興味深かった。
(ただしバージョン管理システムはgitではないらしい)
これは、社内の人間は全てのリソースを閲覧できるようにすべし、常にプロジェクト外の人も改善案を出せるような体制にすべし、ということらしく、こちらも先のセッションのgithubと同じようなポリシーな模様。
※参考
さて、ここから本題のSREについて。
Googleでは、システムをただ運用するだけでなく、安定運用するために必要なソフトウェアの開発を合わせて行う専門のチームがいるとのこと。
このチームがいかに「安定的にサービスを提供し続ける」か、ということをまとめたのがSREとのこと。
まず、GoogleのSREチームには、50%ルールというのがあり、まず業務の50%はシステム安定化に関わるプロジェクト活動に充て、もう50%で運用業務を行う、というのがあるらしい。
これは、SREチームのBurnout(燃え尽き症候群)の防止とともに、とにかくGoogleはToil(マニュアル作業などの労力のかかる仕事)は悪であるという考え方に基づき、マニュアル作業を減らす活動をしてもらうことでモチベーションを保ってもらうという目的があるらしい。
SREの原則は、明確な指標を元にService Level Objective (SLO)を設定することで「安定」の定義化をはかり、そこにおさまる限りはエラーが起きても許容する、という考え方。
どれぐらいエラーを許容できるか、というのはエラーバジェットという指標があり、エラーバジェットは、
(1.0 – SLO(%)) * 100 = エラーバジェット(%)
で求められるとのこと。
このエラーバジェットを指標にして、エラーバジェットが無くなりそうな可能性がある場合には、開発チームと連携して抜本的な対策を講じたりするらしい。
セッションでは他にも、新規開発時には安定稼働を目的としたレビューをSREチームが開発チームに対して行うだとか、障害対応のプロセスを仕組み化して担当者の自動設定と障害のナレッジを共有するようにしたりだとか、SREの手法について詳しく解説していた。
最後に、SREのトレーニングコースがCourseraにあるそうなので、興味のある人は受けてみると良いとのこと。
Site Reliability Engineering: Measuring and Managing Reliability
【15-F-2】 Kubernetesを短時間で体験。IBM Kubernetesで遊んでみよう!(斎藤 和史[日本アイ・ビー・エム]/今関 靖一郎[日本アイ・ビー・エム システムズ・エンジニアリング])
最後に受けたセッションはこちら。
Dockerとかは扱ったことあるけど、何気にKubernetesはいじったことがなかったので、飛び入りで参加してみたハンズオン。
ハンズオンの内容は、こちらにあるチュートリアルにしたがって行われた。
実際使ってみると、結構簡単にレプリケーション数を増やせるし、Dockerfileみたいに定義を書いておけばコマンド一つで1分もかからずにクラスタが作れる。
しかも特定のクラウドに縛られる訳でもなく、awsでもgcpでもIBM Cloudでも使えるの、なかなかに良い。
コマンドもチュートリアル見たらわかるけど、若干dockerじみている感あるし、docker使ったことがある人なら割とサクッと使えるんではないかと。
会場にいたスタッフの方も丁寧に解説してくださり、今後Kubernetes使ってもいいかもなーと思わせるハンズオンでした。
というわけで2日にわたるデブサミ2019年レポ、これで終わりです!!!
色々刺激を受けたし楽しかった!!!!
みんな個人スポンサーはおすすめだよ!!!!
腹が減ったので天一に寄っておうち帰って寝る!!!!!!
