AWS Stepfunctionsのエラー捕捉のデザインパターン
2018.12.1
この記事は WanoグループAdvent Calendar 2018 1日目の記事になります。
なんとまあ今年もアドベントカレンダーの季節です。1年速い……..
re:invent 2018で発表されたStepfunctionsのアップデート
今年も re:invent 2018で大量のサーバーレス周りのアップデートが施されました。
StepFunctionsもその一つで、複数のサービスとの連携が新たに発表されました。
New – Compute, Database, Messaging, Analytics, and Machine Learning Integration for AWS Step Functions
個人的に気になっているのは、FargateタスクやBatchタスクの直接の実行と待ち受けがステートマシン上で可能になったことです。
実行ワークフロー上でコンテナを使うタスクが必要になった時でも、ActivityによるTaskTokenの引き渡しや、やイケてないポーリングループによる実行結果待ちなどが不要になります。
また、DynamoDBと直接の値の参照と変更がステートマシンの文法で可能になったことで、ワークフロー固有ロジック/context的な部分をユースケース層的な感じでステートマシン上に閉じ込め、各実行タスクは自身の作業に集中できるようになり、DRYな環境が保ちやすくなったのかな、と思います。
不満点
とはいえ、まだまだワークフローエンジンとして自分が欲しかったものとして「もうちょっと惜しいなー」という環境であることも確かです。
- Activity や Lambda のイベントにデフォルトで「context_id」的なものを引き継ぎたい
- 「待ち受け」をスッキリ書くためのステートマシン自体の入れ子/再利用機能
- 動的なパラレル機構(これはフォーラムでも前向きに検討中とされていた)
- ステートメント言語自体のアップデート。ステート毎の入出力の柔軟化
- runtime error捕捉もしくはステート遷移のCloudWatch Event対応
…等々。
StepFunctionsにおけるエラー捕捉
なんか色々書いてしまいましたが、今回は、最後のエラー捕捉の話と現状での対策について書いてみようかな、と思います。
StepFunctionsでステートマシン実行時のエラーを捕捉するにはいくつかの方法があるのですが、ここでなかなかハマりどころがありました。
- try/catchパターン
- Runtimeエラー捕捉パターン
この2つについてご紹介します。
try/catchパターン実装
愚直なcatchの問題
Step Functionsではタスクごとにエラーをcatchし、独自の例外処理に分岐できる機構があります。
その時にはもちろん、各タスクごとにエラー処理を書く必要があるのですが、やっとみるとこれがなかなか曲者です。
つらつら書いていくと以下のようになります。
{
"StartAt": "ランダムにエラーを起こすタスク1",
"TimeoutSeconds": 10,
"States": {
"ランダムにエラーを起こすタスク1": {
"InputPath": "$",
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:xxxx:function:lambda-for-blog",
"Next": "ランダムにエラーを起こすタスク2",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "失敗時になんかするタスク"
}
]
},
"ランダムにエラーを起こすタスク2": {
"InputPath": "$",
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:xxxx:function:lambda-for-blog",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "失敗時になんかするタスク"
}
],
"Next": "ランダムにエラーを起こすタスク3"
},
"ランダムにエラーを起こすタスク3": {
"InputPath": "$",
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:xxxx:function:lambda-for-blog",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "失敗時になんかするタスク"
}
],
"Next": "成功"
},
"失敗時になんかするタスク": {
"Type": "Pass",
"Next": "失敗"
},
"失敗": {
"Type": "Fail"
},
"成功": {
"Type": "Pass",
"End": true
}
}
}
実行
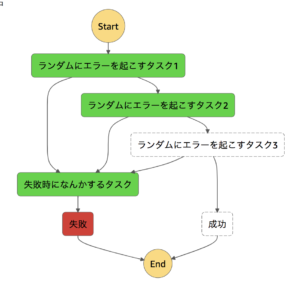
同じ例外処理に行きつきたいだけなのに、Catch部分の設定が頻出し、冗長です。
ステートマシン図上で見たときも、なにやらごちゃごちゃとしてしまいます。
とりあえずParallelタスクで包む
そこで、シンプルな try/catchを実装するには以下のようなパターンがあります。
直列実行でもとりあえずParallelで包んじゃうことです。
{
"StartAt": "初期タスク",
"TimeoutSeconds": 10,
"States": {
"初期タスク": {
"Type": "Parallel",
"Next": "成功",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "失敗時になんかするタスク"
}
],
"Branches": [
{
"StartAt": "ランダムにエラーを起こすタスク1",
"States": {
"ランダムにエラーを起こすタスク1": {
"InputPath": "$",
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:xxxxx:function:lambda-for-blog",
"Next": "ランダムにエラーを起こすタスク2"
},
"ランダムにエラーを起こすタスク2": {
"InputPath": "$",
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:xxxxx:function:lambda-for-blog",
"End" : true
}
}
}
]
},
"失敗時になんかするタスク": {
"Type": "Pass",
"Next": "失敗"
},
"失敗": {
"Type": "Fail"
},
"成功": {
"Type": "Pass",
"End": true
}
}
}
実行
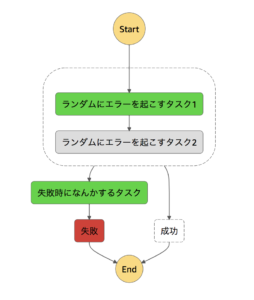
Runtimeエラー捕捉パターン実装
runtimeエラーが捕捉できない
しかし、これでも1つ問題があります。
エラー待ち受けパターンの "States.ALL" でもRuntimeエラーの捕捉は出来ないということです。
Runtimeエラーというのは、各種タスクの実行の「中」で出力されたエラーではありません。
多くはステート間のjsonの引き渡し中に発生し、値の捕捉に失敗するケースで発生します。
基本的には起こさないのが当然だろう、という見方もあるのですが、複雑なアプリケーションになり、大きなjsonを引き渡し加工していくようなユースケースになると、十分起こりえるかな、とも思います。
その際、確実にこのワークフローのエラー自体を捕捉し、何か個別にアクションを起こす必要が生じます。
ですが、Cloudwatchアラームでは個別のステートマシンの実行内容については感知できませんし、 CloudWatch EventでもStepFunctionsのステートの変更イベントは 個別に捕捉できない ので、そちらで対応するのも現在のところ無理そうです。
ステートマシンのエラー捕捉用のステートマシン
苦肉の策として、ステートマシンの特定の実行自体をモニタリングするステートマシンを作る、というパターンがあります。
具体的には、実行したいStepFunctions(A)の実行時に、同時にそのarnを引き渡し、監視用のステートマシンを実行させます。
監視用ステートマシンは、引き渡されたarnから監視対象のステートマシンが完了かエラー状態になるまで随時ループで読み取っていきます。
{
"StartAt": "Wait",
"States": {
"Wait": {
"Type": "Wait",
"Seconds": 10,
"Next": "WatchStateMachineStatus",
"OutputPath": "$"
},
"WatchStateMachineStatus": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:xxxxxx:function:stepfuncrions-runtime-error-kansi",
"Next": "StatusCheck",
"ResultPath": "$",
"OutputPath": "$"
},
"StatusCheck": {
"Type": "Choice",
"OutputPath": "$",
"Choices": [
{
"Variable": "$.status",
"StringEquals": "RUNNING",
"Next": "Wait"
},
{
"Variable": "$.status",
"StringEquals": "SUCCEEDED",
"Next": "End"
},
{
"Variable": "$.status",
"StringEquals": "ERROR",
"Next": "DispatchFail"
}
],
"Default": "DispatchFail"
},
"DispatchFail": {
"Type": "Pass",
"Next": "End"
},
"End": {
"Type": "Pass",
"End": true
}
}
}
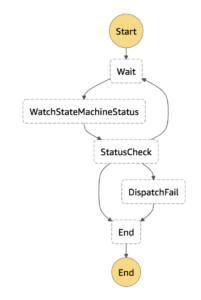
監視用Lambda Functions
const AWS = require("aws-sdk");
const stepfunctions = new AWS.StepFunctions({apiVersion: '2016-11-23' , region : "ap-northeast-1"});
exports.handler = async (event) => {
const params = {
executionArn: event.arn
};
const r = await stepfunctions.describeExecution(params).promise();
const status = r.status;
if (status == `RUNNING`){
return {
arn: event.arn,
status : `RUNNING`
}
}
if (status == `SUCCEEDED`){
return {
arn: event.arn,
status : `SUCCEEDED`
}
}
return {
arn: event.arn,
status : `ERROR`
}
};
まとめ
以上2パターンをご紹介しました。
StepFunctionsはちょっとした非同期タスクつなぎのユースケースでは使えるのですが、
もっと複雑なワークフローを構築する必要が出てくると、まだまだごちゃごちゃとしたハックが必要になってしまうので、業務ではSQSベースのオレオレワークフローエンジンを実装してしまいました。
ですが、「どこでなにが起こっているか」の図示やワークフローごとのログの集約が図れるので、基本的にはとてもいいツールだと思っています。
他で挙げた不満点に関しても実は度々フォーラムで上がっているのを見かけるので、対応されるととっても嬉しいな!と期待しております。
